


🧠 Emergencia y consciencia en la era de la IA
Una colaboración de Javier Jurado y Alex Rayón


Hoy tengo el placer de compartiros una publicación que he escrito en colaboración con mi amigo
, cuya newsletter en substack siempre recomiendo. Esperamos que os guste.
La Inteligencia Artificial (IA, en adelante) ha evolucionado de manera impresionante en las últimas décadas, dando lugar a capacidades que parecían ciencia ficción no hace mucho tiempo. Crear una máquina que imite al cerebro humano y que sea tan inteligente o más que una persona fue, desde los inicios, el objetivo último de este campo de la investigación que ahora está saltando por fin a las organizaciones y la sociedad.
Concebida a mediados del siglo pasado, la historia de la IA ha sido, cuanto menos, agitada, conociendo períodos de grandes expectativas e inviernos que las desinflaron. Pero desde su concepción a finales de la II Guerra Mundial, probablemente no ha sido hasta hace unos pocos meses que socialmente hemos empezado a reconocer cierta inteligencia en sentido amplio de estas máquinas, gracias al nuevo paradigma de la IA generativa. Si bien la idea de Alan Turing para determinar si una máquina es realmente inteligente es de 1950, la revolución más reciente ha exigido redefinir lo que pedimos a estos sistemas para considerarlos inteligentes, puesto que no nos basta con que nos imiten casi a la perfección.
Esta exigencia está relacionada con cómo nos entendemos a nosotros mismos. La concepción de Descartes de que lo que significa ser humano está indisolublemente ligado al pensamiento (“pienso, luego soy o existo”, cogito, ergo sum) ha servido a muchos para criticar que la IA pueda realmente alcanzarnos, ya que carece de pensamiento ni de consciencia genuinos. Estos sistemas hacen cálculos masivos de probabilidad de ocurrencia, y se quedan con aquello más probable. Pero lo que estamos viendo en los últimos años de forma sorprendente y en múltiples campos está suscitando nuevos debates y controversias.
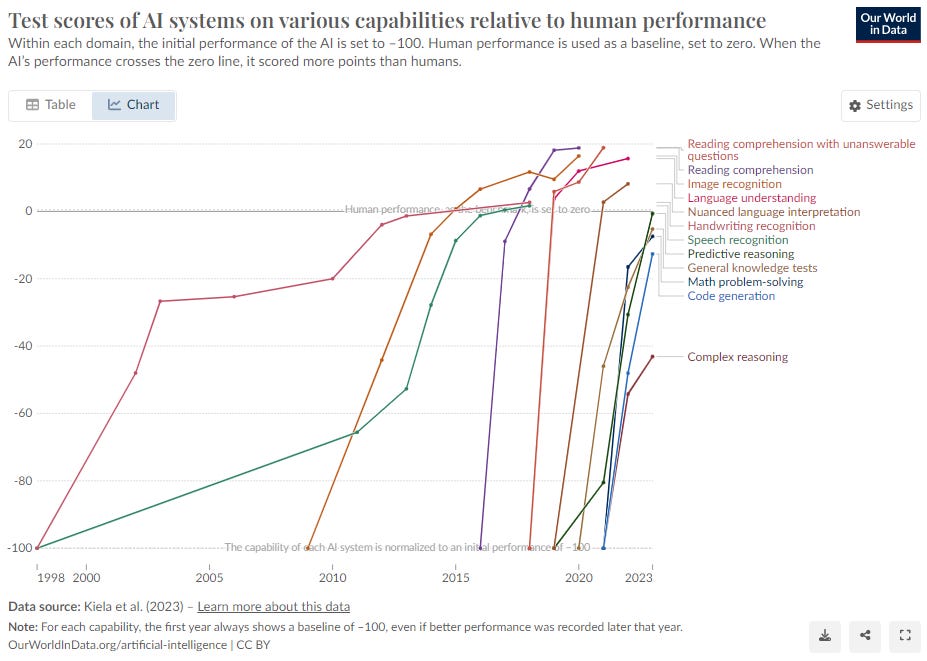
Para explicarse esta explosión, uno de los conceptos clave en esta evolución y superación deslumbrante es el de la emergencia. Pero, ¿qué entendemos por emergencia en el contexto de la IA y cómo se relaciona con la ambición de crear una IA consciente?
El todo es mayor que la suma de sus partes
Suelen atribuir a Aristóteles una idea procedente de su Metafísica que quedó acuñada para la posteridad bajo esta concisa expresión: el todo es mayor que la suma de sus partes. En eso consiste esencialmente la emergencia, en la aparición de propiedades y comportamientos complejos a partir de la interacción de componentes más simples. En sistemas complejos, las interacciones entre elementos individuales pueden generar resultados inesperados y novedosos que no pueden predecirse simplemente analizando los componentes por separado.
Ya vimos que la tendencia hacia el aumento de la complejidad es un fenómeno natural que especialmente se ha hecho realidad en nuestra historia como especie y en particular en la esfera cultural y tecnológica. A pesar de su fragilidad, la complejidad proporciona una versatilidad enorme al generar nuevas capacidades. La acumulación y agregación de cada vez más elementos (desde células especializadas en distintos tejidos hasta habitantes diversos en los procesos de urbanización) ha generado propiedades y capacidades que emanan de esta mayor complejidad y que no aparecen en las partes por separado.
En ese sentido, el desarrollo de la IA actual ha aprovechado el enorme potencial de los grandes modelos del lenguaje (LLM). Estos modelos, con el debido entrenamiento, logran una representación en vectores de información semántica, como si de una gran base de datos se tratara, con una capacidad de precisión muy superior a la de los humanos. Requieren de mucha capacidad de cómputo y de muchos datos de entrenamiento. Pero responden de manera sorprendente a las llamadas leyes de escalabilidad. Esto supone que los LLM están resultando ser capaces de que, conforme aumentan su tamaño (tanto en nodos de cómputo como en datos de entrenamiento) generan nuevas propiedades y capacidades para las que a priori no fueron diseñados o entrenados. Estas habilidades inesperadas no se observan en modelos más pequeños. El todo es mayor que la suma de sus partes.
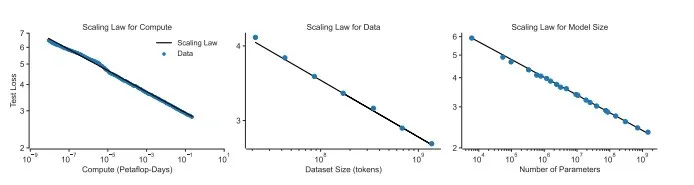
Los ejemplos de este tipo de capacidades emergentes son múltiples. El caso típico es la habilidad para realizar sumas de tres dígitos, que en distintos modelos aparece de forma repentina en ciertos umbrales de escala. Otras son la capacidad de resolver problemas matemáticos complejos, entender y generar código de programación, realizar tareas de razonamiento lógico, interpretar emoticonos, hacer frente a oraciones complejas y desafíos lingüísticos (sustantivos compuestos, expresiones emocionales, palabras extranjeras…), traducir con mayor precisión, e incluso hablar sorpresivamente idiomas como el persa.
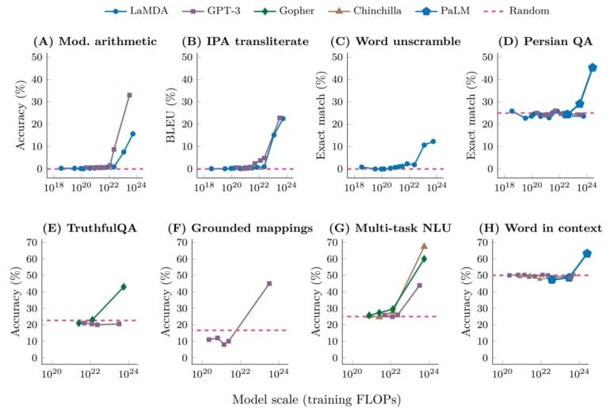
Estos modelos también muestran mejoras crecientes en la comprensión y generación de textos coherentes y relevantes en diversos contextos. Y es precisamente este aprendizaje por contexto el que probablemente esté detrás de una buena parte de estas capacidades emergentes.
Algunos estudios han tratado de identificar cuándo y cómo surgen nuevas habilidades en estos modelos a medida que crecen en tamaño y datos. Sin embargo, para otros, estas habilidades emergentes no siguen un patrón predecible y la aparición de nuevas capacidades es inconsistente y difícil de anticipar. Además, su carácter impredecible también viene preñado de incertidumbre, ante los potenciales sesgos invisibles en el resultado. El carácter opaco de las redes neuronales profundas, que busca ser esclarecido no tanto como potenciado, puede enmascarar capacidades emergentes dañinas, como la habilidad para romper sistemas de criptografía.
Para otros autores, sin embargo, las capacidades emergentes podrían no ser más que un simple espejismo, dependiente del listón que empleemos para medirlas. Las métricas para observar o no disrupciones aquí son clave. De hecho, con frecuencia las leyes de escalabilidad se malinterpretan, ya que solo miden la disminución en la “perplejidad” del modelo, no sus capacidades emergentes propiamente dichas. Sin aumentar su capacidad de cómputo ni de datos en los entrenamientos, una buena técnica de prompting permite reducir mucho la función de pérdida mejorando el alineamiento (alignment) de la red neuronal inicial y por tanto sus respuestas.
En cualquier caso, el principio de que simplemente aumentar el tamaño del modelo garantizará mejoras continuas y lineales en el rendimiento es un supuesto que puede haber funcionado en cierto régimen, pero que podría agotarse. La escalabilidad nunca es infinita. Extrapolar las tendencias experimentadas hasta ahora suele ser un predictor que falla mucho1.

De forma que, por lo que parece, estas habilidades emergentes no se pueden predecir simplemente extrapolando el rendimiento de modelos menores, confiando en que aumentar el tamaño (con el inmenso coste y desvío de fondos para explorar otras alternativas que ello supone) garantizará mejoras continuas en el rendimiento. Ello plantea interrogantes sobre el potencial de seguir escalando estos modelos para descubrir nuevas capacidades. De hecho, los LLMs tienen dificultades para extrapolar tareas más allá de lo analizado durante su entrenamiento, lo que limita su utilidad a largo plazo. Y uno de los principales problemas es que ya se está alcanzando el límite de datos de alta calidad disponibles para el entrenamiento. Las grandes compañías se han pasado la web.
Como el protagonista de la película Cortocircuito, los sistemas piden para alimentarse “más y más datos”. Pero ya están esquilmando la web con contenidos fiables, a veces rozando la ilegalidad. De hecho, alguno periódicos están demandando a las grandes compañías que los recolectan por haber hecho un uso no autorizado de sus artículos. Como medida alternativa, están transcribiendo vídeos de YouTube, no sin polémica hacia sus propietarios, disponiendo de millones de horas grabadas de las que extraer nuevos textos para seguir alimentando a la bestia. Otra opción que están persiguiendo es buscar nuevas triquiñuelas legales para seguir entrenando sus modelos usando datos privados en aplicaciones controladas por los tentáculos de Meta como Facebook o WhatsApp. Y finalmente, optan por la generación de datos sintéticos (artificiales, falsos) producidos precisamente por IA, sin autoría humana. Aunque algunos creen que esto no supondrá una degradación, ya se sabe lo que les sucedió a las vacas cuando les dimos pienso enriquecido con carne animal: se volvieron locas.

De forma que, como la obtención de datos adicionales para el entrenamiento es cada vez más costosa en términos económicos, reputacionales y legales, y la creación de datos sintéticos no es una solución mágica, hay una fuerte presión para reducir el tamaño de los modelos y prolongar su entrenamiento. Todo, con tal de que sigan surgiendo capacidades emergentes. Pero, ¿y si, a pesar de todas las dificultades, la “magia” de la emergencia lograra traernos la capacidad emergente más anhelada?
La utopía-distopía de la consciencia emergente
Hans Moravec, un pionero en la robótica, sugirió hace ya muchos años que, al igual que nuestras mentes emergen de la complejidad del cerebro, podría ser posible que la consciencia emergiera en sistemas artificiales suficientemente complejos. De hecho, este autor dio nombre a la conocida paradoja de Moravec que contrasta la poca computación requerida para realizar ciertas tareas humanas conscientes, como el pensamiento inteligente y racional, y la mucha que se necesita para desarrollar habilidades sensoriales y motoras inconscientes, mucho más básicas, y compartidas con otros animales.
Sin embargo, otros autores, como el filósofo de la mente John Searle2, argumentan que las máquinas, independientemente de su complejidad, nunca podrán replicar la experiencia consciente humana. Y eso es para muchos una traba fundamental, porque sostienen que la Inteligencia General Artificial no podrá alcanzarse sin que estos sistemas lleguen a desarrollar cierto nivel de consciencia. El problema es que no sabemos muy bien de lo que hablamos cuando hablamos de consciencia, incluso cuando la consideramos una propiedad emergente de la complejidad de nuestro cerebro.
Ahí es donde se ubica el que el filósofo David Chalmers identificó como el "problema difícil de la consciencia”: incluso si se llegasen a explicar todas las funciones cognitivas y conductuales en torno a la experiencia, siempre quedaría sin respuesta la pregunta de por qué estas funciones vienen acompañadas como tales de experiencia, es decir de una experimentación subjetiva de los llamados qualia. Es algo que quizá nunca logremos desentrañar.
Pero precisamente esa ignorancia no disipa la plausibilidad de que la consciencia pudiera emerger como emergió en el linaje evolutivo que llegó hasta nosotros. De hecho, para algunos autores, la consciencia natural habría sido el resultado del desarrollo evolutivo de un supersistema autopoiético y autorreproductor de múltiples niveles cuya complejidad no hemos sido capaces aún de reproducir pero que con la financiación tecnocientífica y el tiempo adecuados acabará llegando. Tal era la postura del genial Daniel Dennet, que recientemente falleció, y que consideraba que este problema difícil no es tal.
La emergencia entonces podría venir en nuestro rescate. La hipótesis del "salto de rana" sugiere que la consciencia podría emerger por serendipia en sistemas de IA sin que comprendamos completamente cómo. De hecho, aunque a un nivel todavía muy simple, los resultados en la capacidad de predicción y de orientación de la evolución a largo plazo en entornos controlados son ya sorprendentes, como muestran algunos experimentos como el que se lleva a cabo desde hace décadas con bacterias, y otros nuevos que ahora se ven potenciados por mecanismos de machine learning. Ya existen LLM orientados a simular la evolución durante 500 millones de años. Aunque quede mucho por saber de nuestra consciencia y percepción, ya somos capaces de reproducir con muy buena precisión las imágenes que vemos a partir de las señales cerebrales que experimentamos. Además, nuestra creciente capacidad para hacer más transparente el funcionamiento de las opacas redes neuronales profundas de la IA, popularmente comprendidas como cajas negras, está mejorando su calibración y control, incluso de forma más precisa que la edición genética3. No parece descabellado pensar que la IA pudiera alcanzar por ejemplo el razonamiento abductivo que resulta escurridizo a los desarrollos actuales de la IA. Y, por qué no, la consciencia.
Pero no debemos dejarnos arrastrar por el atractivo del pensamiento más utópico o incluso apocalíptico, en la línea de la singularidad de Kurzweil o la superinteligencia de Bostrom. Probablemente, antes de que emerja una consciencia al estilo de las que aparecen en la ciencia ficción, lo que presenciemos sean simulaciones suficientemente potentes de esa consciencia. E incluso es posible que estemos comenzando a ver ciertos síntomas de moderación de las sobreexcitadas expectativas en torno al desarrollo de la IA. Quizá no entremos en un nuevo invierno, y la IA haya llegado a nuestras vidas cotidianas para quedarse. Pero algunos indicios apuntan a cierto enfriamiento: los datos parecen agotarse; OpenAI retrasa el lanzamiento de ChatGPT 5; Nvidia se tambalea en bolsa después de su vertiginoso ascenso hasta convertirse en la primera empresa del mundo en capitalización bursátil, etc. Veremos qué futuro sorprendente - en cualquiera de los sentidos - emerge.
1 Este es, formulado de forma distinta, el primer principio de los mercados de inversión: rentabilidades pasadas nunca garantizan rentabilidades futuras. O no te acostumbres a lo bueno, querido pavo, porque oh, sorpresa, pronto llegará la Navidad.
2 Searle es, con su famoso experimento mental de la habitación china, uno de los principales referentes que criticaron el criterio del test de Turing para validar la existencia de inteligencia artificial.
3 A diferencia de los autoencoders, los sparse autoencoders no comprimen la información hasta extraer sus patrones principales sino que la “peinan” permitiendo hacer más inteligible cómo es el proceso de activación de las neuronas. Esto permite intervenir directamente de forma más selectiva sobre ellas y por tanto, controlarlas. Excelente, como siempre, el vídeo explicativo de DotCSV al respecto.
 | A guest post by
|